








湖北日報訊 (通訊員林俊特)9月24日,2025云棲大會現場,阿里云接連發布了七款大模型技術產品。七款技術產品覆蓋語言、語音、視覺、多模態、代碼等模型領域,在模型智能水平、Agent工具調用以及Coding能力、深度推理、多模態等方面均實現突破。

在大語言模型中,阿里通義旗艦模型Qwen3-Max全新亮相。Qwen3-Max是通義千問家族中最大、最強的基礎模型,擁有極強的Coding編程能力和Agent工具調用能力,性能躋身全球前三。
下一代基礎模型架構Qwen3-Next及系列模型也正式發布,實現模型計算效率的重大突破。Qwen3-Next針對大模型在上下文長度和總參數兩方面不斷擴展的未來趨勢而設計,長文本推理吞吐量提升10倍以上,為未來大模型的訓練和推理的效率設立了全新標準。
在專項模型方面,千問編程模型Qwen3-Coder重磅升級,代碼生成和補全能力極強,可一鍵完成完整項目的部署和問題修復。

在多模態模型中,視覺理解模型Qwen3-VL重磅開源,在視覺感知和多模態推理方面實現重大突破。Qwen3-VL擁有極強的視覺智能體和視覺Coding能力,不僅能看懂圖片,還能像人一樣操作手機和電腦,自動完成許多日常任務。輸入一張圖片,Qwen3-VL可自行調用agent工具放大圖片細節,通過更仔細的觀察分析,推理出更好的答案;看到一張設計圖,Qwen3-VL 就能“所見即所得”地完成視覺編程。
全模態模型Qwen3-Omni驚喜亮相,可像人類一樣聽說寫,應用場景廣泛,未來可部署于車載、智能眼鏡和手機等。用戶還可設定個性化角色、調整對話風格,打造專屬的個人IP。
通義萬相是通義大模型家族中的視覺基礎模型,此次推出Wan2.5-preview系列模型,涵蓋文生視頻、圖生視頻、文生圖和圖像編輯四大模型。通義萬相2.5視頻生成模型,能生成和畫面匹配的人聲、音效和音樂BGM,進一步降低電影級視頻創作的門檻。此次,通義萬相2.5還全面升級了圖像生成能力,可生成中英文文字和圖表,支持圖像編輯功能,輸入一句話即可完成P圖。

阿里云CTO周靖人發布通義百聆
此次云棲大會上,通義大模型家族還迎來了全新的成員——語音大模型通義百聆。百聆發布了語音識別大模型Fun-ASR和語音合成大模型Fun-CosyVoice。Fun-ASR具備強大的上下文理解能力與行業適應性;Fun-CosyVoice可提供上百種預制音色,可以用于客服、銷售、直播電商、消費電子、有聲書、兒童娛樂等場景。
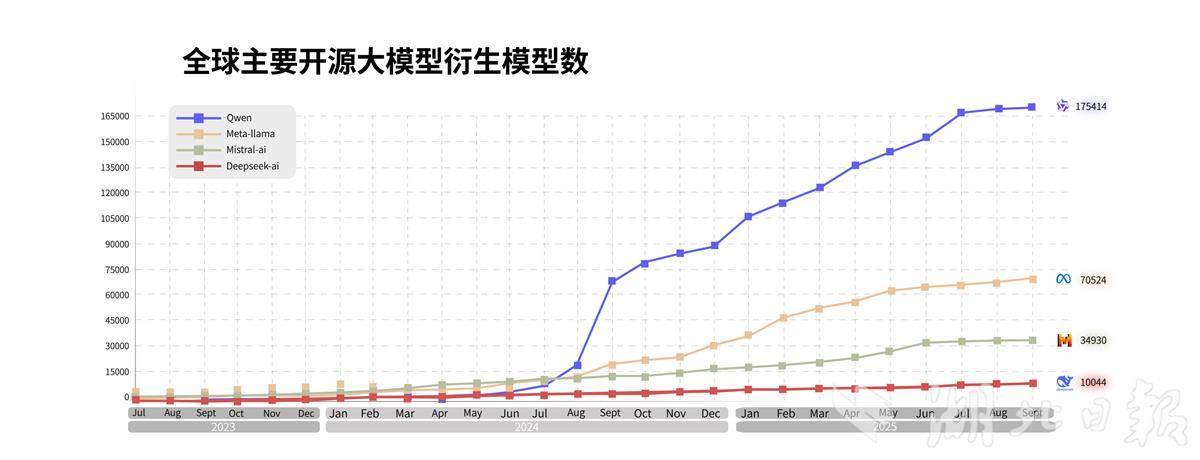
自2023年開源第一款模型以來,通義大模型在全球下載量突破6億次,衍生模型突破17萬個,已發展成為全球第一開源模型。除了惠及AI開發者,通義衍生模型的開發機構還覆蓋海內外國知名企業,包括蘋果、英偉達、微軟、DeepSeek和字節跳動等。截至目前,通義大模型已服務超100萬客戶。沙利文報告顯示,2025年上半年,在中國企業級大模型調用市場中,通義位列第一。
Copyright ? 2001-2025 湖北荊楚網絡科技股份有限公司 All Rights Reserved
互聯網新聞信息許可證 4212025003 -
增值電信業務經營許可證 鄂B2-20231273 -
廣播電視節目制作經營許可證(鄂)字第00011號
信息網絡傳播視聽節目許可證 1706144 -
互聯網出版許可證 (鄂)字3號 -
營業執照
鄂ICP備 13000573號-1  鄂公網安備 42010602000206號
鄂公網安備 42010602000206號
版權為 荊楚網 www.cnhubei.com 所有 未經同意不得復制或鏡像


